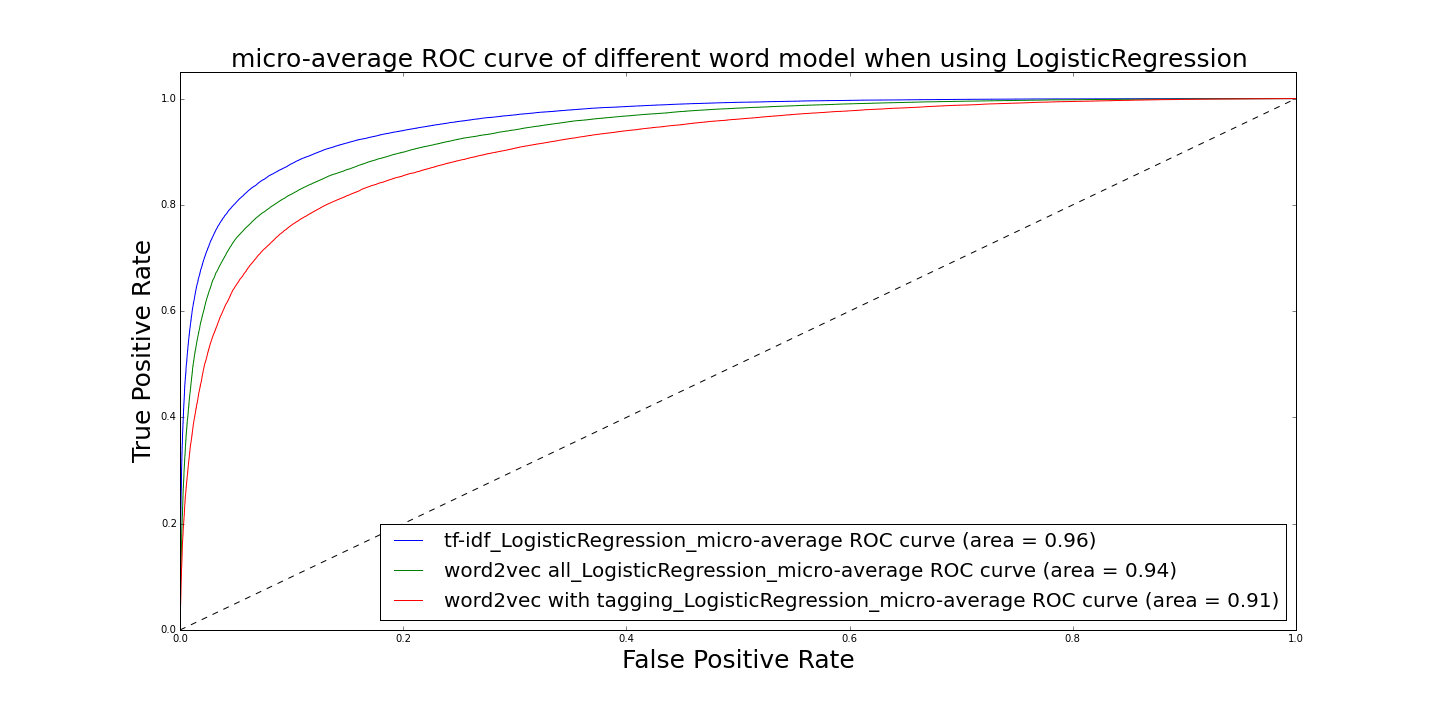
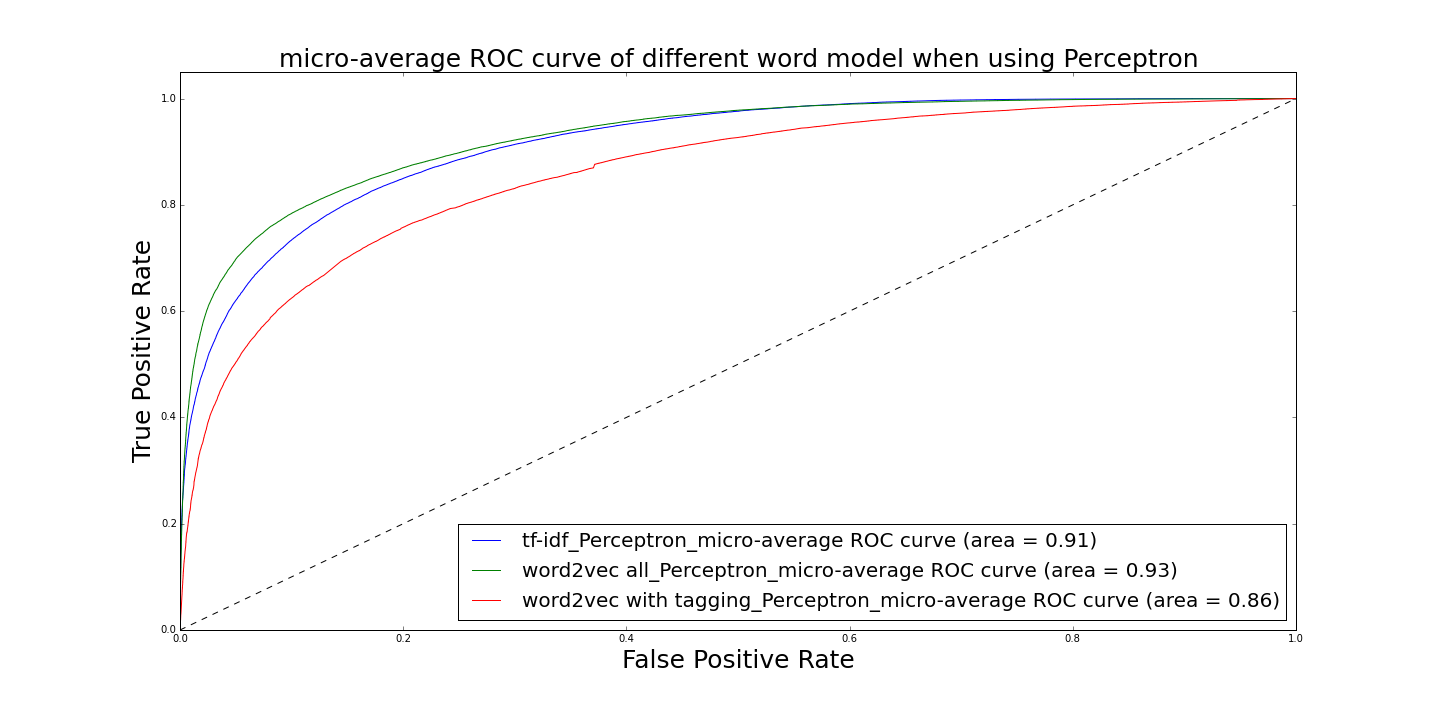
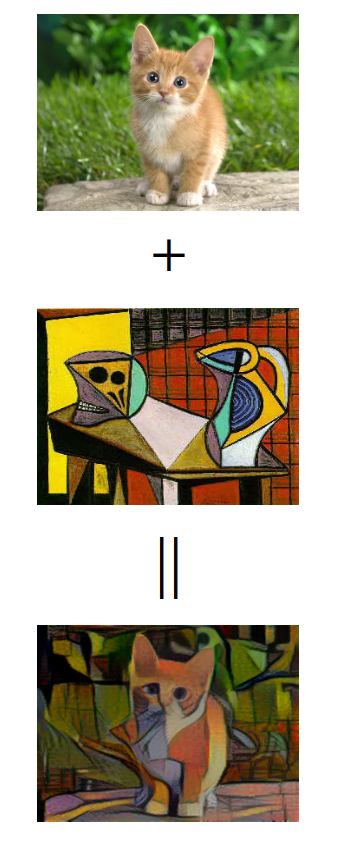
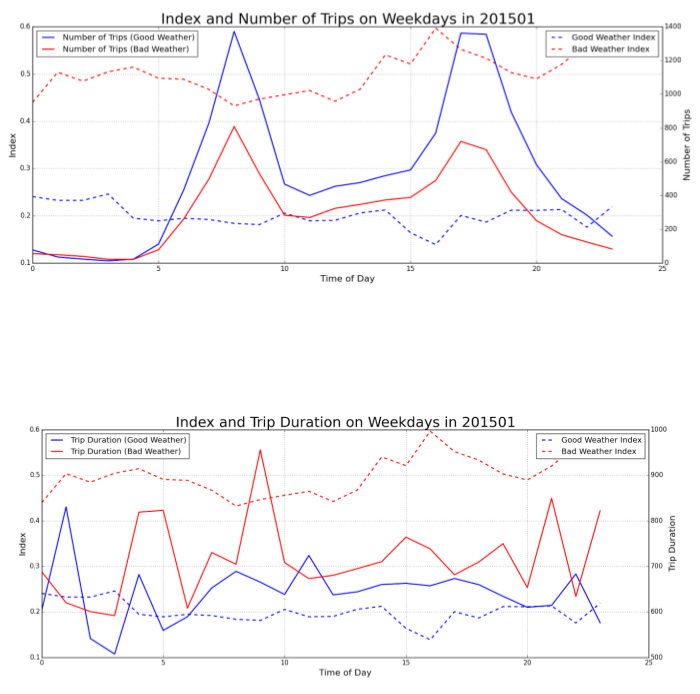
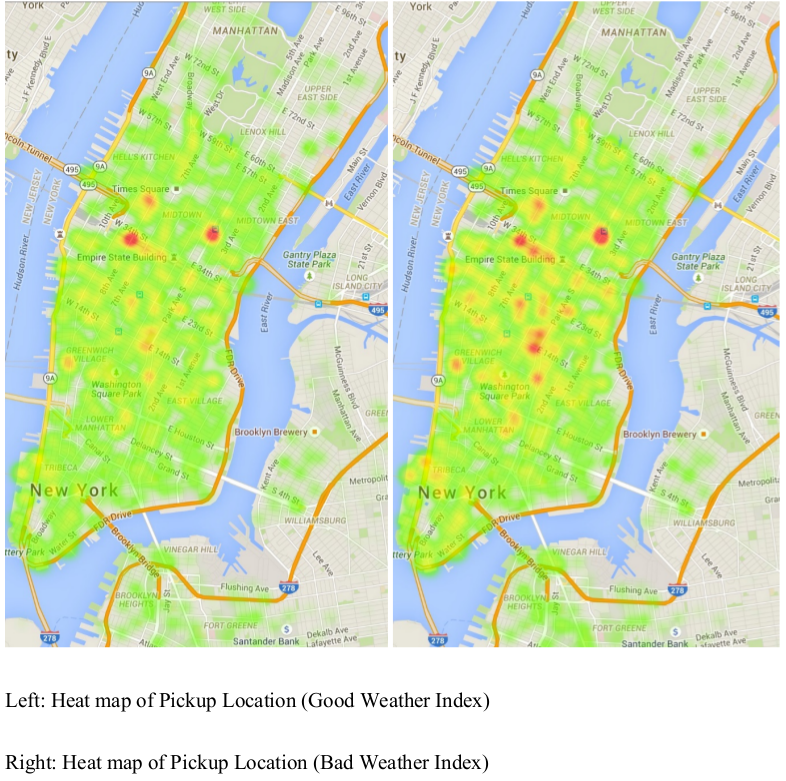
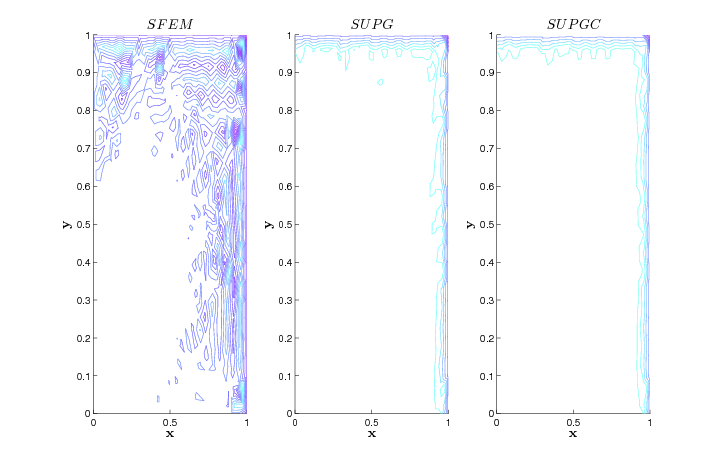
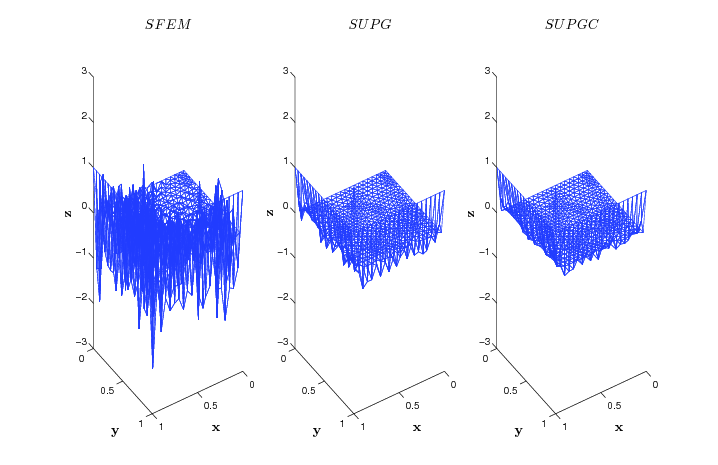
I'm currently working in National Grid. I mainly work with my client to analyze data or build up an end-to-end system to automate the whole process.
Prior to this, I majored in data science in Center for Data Science, NYU. My main interest and research focus on Machine learning, deep learning especially in theorem and application of NLP, Adversarial Network, transfer learning.
I also worked as research intern in AIG Inc. with computer vision group in 2016. I implemented a new method to extract important information from a pretrained model, which is proven to be much better than the previous one after several experiments.
I received my honored B.S in Computational Mathematics from Nanjing University. During that time, I mainly worked with Professor Zhang Qiang in numerical solution of partial differential equation (PDE).
-
I am now working in National Grid as data scienctist. -- Since 09/2017